一、节点介绍
1.1 开始节点
开始节点支持各种的输入类型,coze的各种格式的输入输出都是使用json格式进行传递的,输入节点整体就是一个json对象
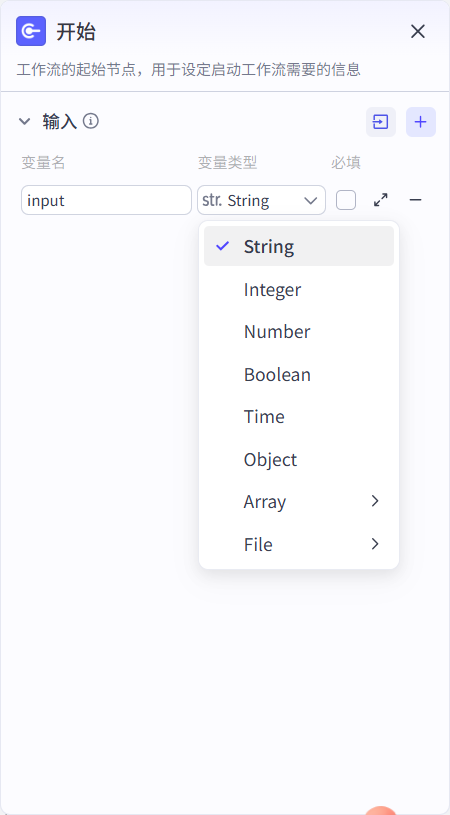
1.2 结束节点
结束节点会输出各种类型的json数据
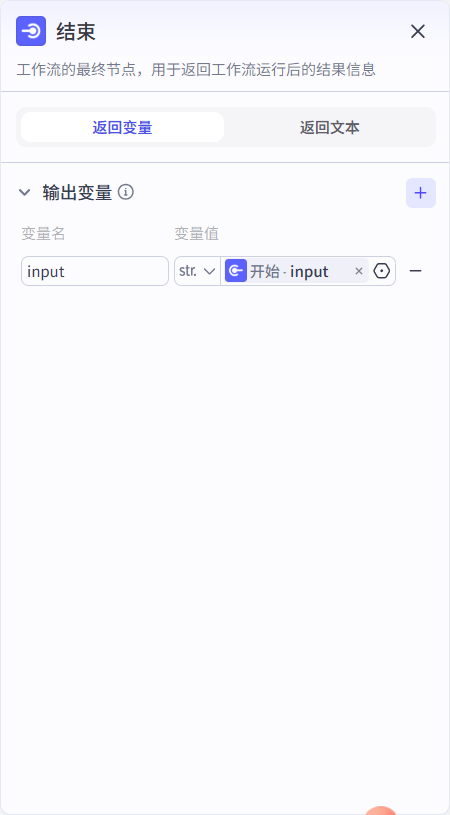
提问:在coze工作流中,对于一个数据流是采取“分散”还是“打包”的方式来进行?
回答:
如果数据之间有明确的“父子”或“整体”关系 → 用 Object 串联,让数据流更聚合。
如果数据彼此独立,且后续处理只涉及其中的一部分 → 用多个独立变量,避免不必要的数据嵌套。
1.3 大模型节点
大模型节点可以支持插件(技能)、模型、工作流和知识库等多种配置,是工作流中最基础和核心的节点。
大模型的输入是“需要添加到提示词中的动态内容”。这里是可以和系统提示词和用户提示词进行结合分析的内容。
系统提示词和用户提示词是大模型节点的核心功能
模型的系统提示词,用于指定人设和回复风格。支持直接插入提示词库中的提示词模版、插入资源库下已创建的提示词,也可以自行编写提示词。编写系统提示词时,可以引用输入参数中的变量、已经添加到大模型节点的技能,例如插件工具、工作流、知识库,实现提示词的高效编写。例如{{variable}}表示直接引用变量,{{变量名.子变量名}}表示引用 JSON 的子变量,{{变量名[数组索引]}}表示引用数组中的某个元素。
模型的用户提示词是用户在本轮对话中的输入,用于给模型下达最新的指令或问题。用户提示词同样可以引用输入参数中的变量。
输出,指定此节点输出的内容格式与输出的参数。
提问:既然模型可以加入插件,问什么还需要单独的处理节点,例如图像生成?
回答:大模型里面的插件是大模型自主决策会不是使用的节点,他决定了什么时候调用,调用什么参数,是不固定的对话场景。而工作量的独立节点是我们自己决策的,是必须执行的过程。
系统提示词和用户提示词的区别辨析,系统提示词是一种为稳定的角色设定,比较稳定,而对于用户提示词是在不断变化中不断更改,依据当前任务来进行判断的,那么用户提示词的作用是什么?
作用是,它本身不是用来“优化”对话的,它是用来让对话成为可能的。
[
{ "role": "system", "content": "你是xxx,语气xxx..." },
{ "role": "user", "content": "今天天气怎么样?" }
]“用户提示词是一次对话任务的整理,系统提示词是整个人设的设定。”
在实际的开发过程中,我们是利用用户提示词来把大模型的输入加进去的,可以看文本解析工作流的具体操作
1.4 代码节点
代码节点的输入是声明需要使用的变量,而代码是需要执行的片段
这里有一定的使用规范
代码节点中需要执行的代码片段,你可以直接编写。
引用变量:直接使用输入参数中的变量,通过return一个对象来输出处理结果。
函数限制:不支持编写多个函数。即使仅有一个输出值,也务必保持以对象的形式返回。
支持 JavaScript 和 Python 两种语言。
1.5 选择器节点
选择器节点是一个 if-else 节点,当存在多个条件分支时,将根据优先级排序逐个判断条件是否成立,若均不成立则只运行“否则”分支。
1.6 意图识别节点
更加有效的分类节点,使用这个节点,可以更好的识别用户的用途并且划分到不用的分支上去
1.7 循环节点
循环是一种常见的控制机制,用于重复执行一系列任务,直到满足某个条件为止。
1.8 变量聚合节点
二、联网搜索工作流
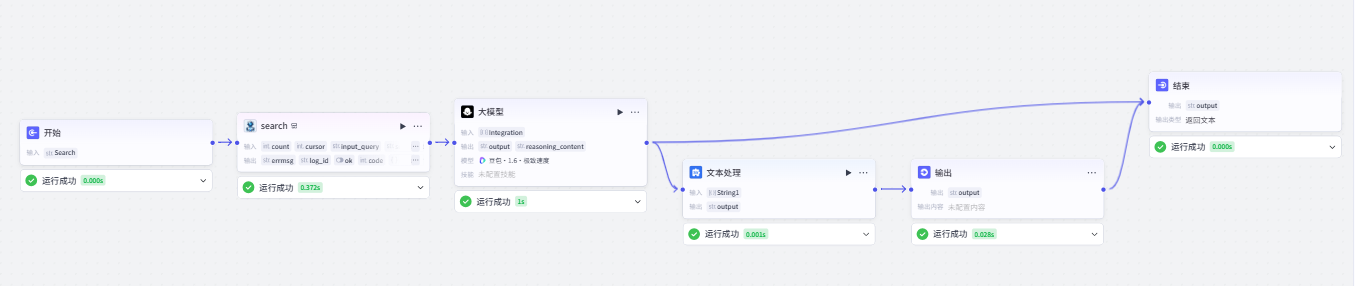
使用 头条搜索数据,对数据进行搜索,文本处理对数据进行拼接,大模型整合到最终结果
联网搜索中所使用的(头条搜索 search)这一类的插件,我们可以把数据传入的时候,传入一个Array<Object>类型的数据,可以多介绍一点信息,后续可以根据这个结构来选择参数
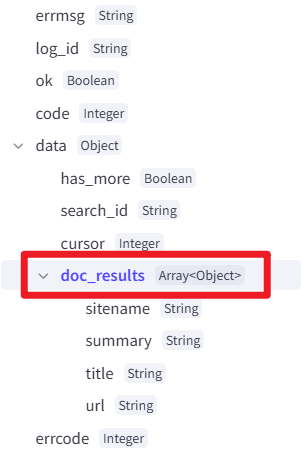
1. [{{String1[0].title}}]({{String1[0].url}})
2. [{{String1[1].title}}]({{String1[1].url}})三、文本解析工作流
由于文本解析需要传入文件,所以可以在开始节点中填充,一个File<Default> 类型的参数和用户提问的input参数。同时需要注意,这里的输入是两种,所以大模型的输入应该也是两种。
其次在大模型解析的时候,一般都是将输入作为用户提示词来进行解析和总结,对于这次对话,用户提示词就是这次的总结。
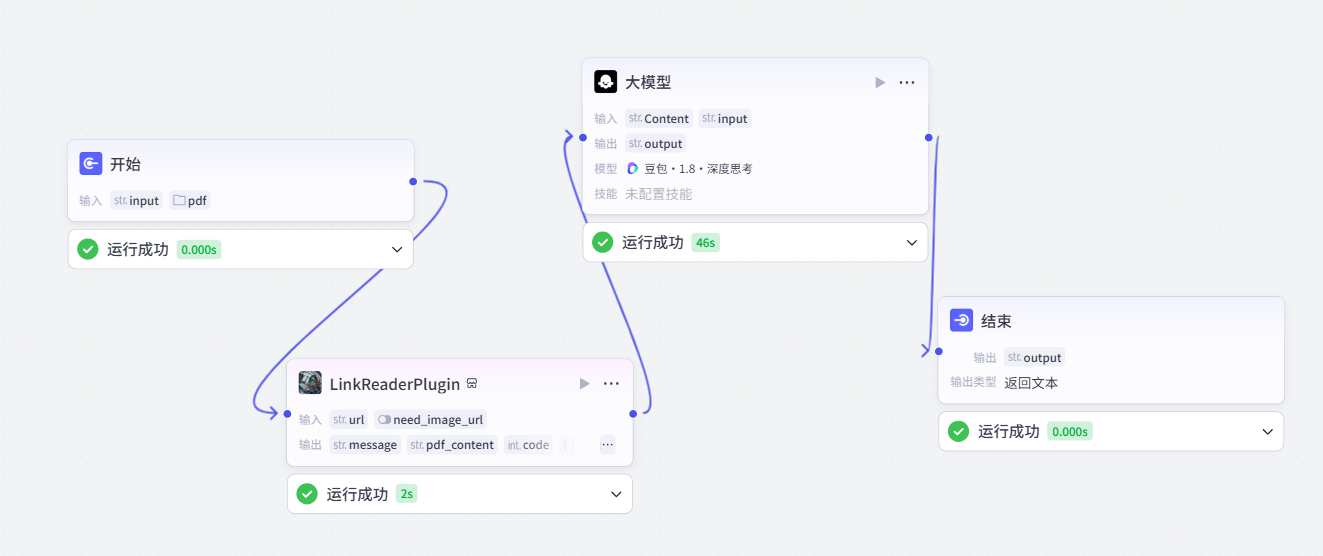
四、代码节点
代码节点主要是编写代码来实现的
# 在这里,您可以通过 'args' 获取节点中的输入变量,并通过 'ret' 输出结果
# 'args' 已经被正确地注入到环境中
# 下面是一个示例,首先获取节点的全部输入参数params,其次获取其中参数名为'input'的值:
# params = args.params;
# input = params['input'];
# 下面是一个示例,输出一个包含多种数据类型的 'ret' 对象:
# ret: Output = { "name": '小明', "hobbies": ["看书", "旅游"] };
async def main(args: Args) -> Output:
params = args.params
# 构建输出对象
ret: Output = {
"key0": params['input'] + params['input'], # 拼接两次入参 input 的值
"key1": ["hello", "world"], # 输出一个数组
"key2": { # 输出一个Object
"key21": "hi"
},
}
return ret