coze智能体访问链接:小北客析 -智能体 - 扣子
该项目由两条工作流组成,对于客服的问答进行智能分析,目前主要完善了工作流,后续可以完善提示词工程等需求。
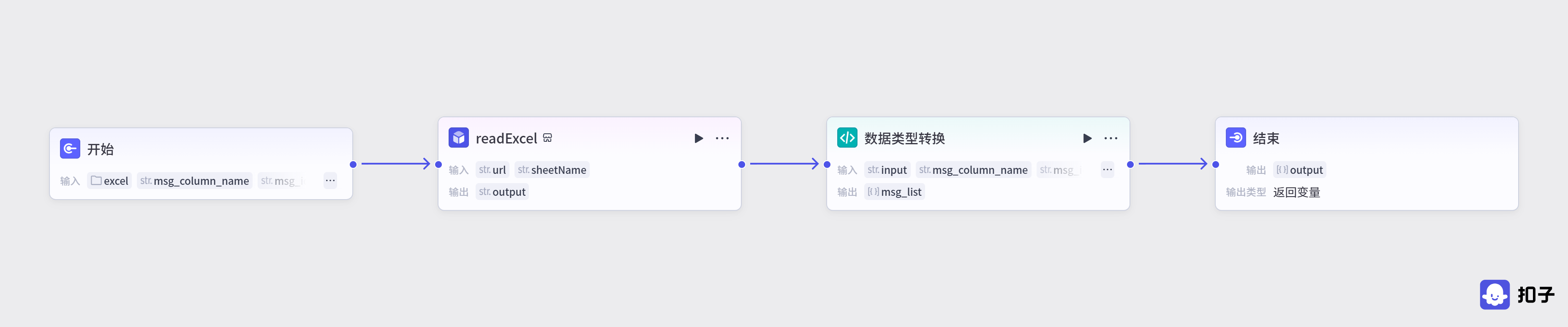
第一条工作流是对Excel表格进行处理,并且进行数据转换,使用的有节点有 readfile 和代码节点
节点中,仅需要输入两个变量,简单易上手。
对于代码节点,示例代码如下
# 在这里,您可以通过 'args' 获取节点中的输入变量,并通过 'ret' 输出结果
# 'args' 已经被正确地注入到环境中
# 下面是一个示例,首先获取节点的全部输入参数params,其次获取其中参数名为'input'的值:
# params = args.params;
# input = params['input'];
# 下面是一个示例,输出一个包含多种数据类型的 'ret' 对象:
# ret: Output = { "name": '小明', "hobbies": ["看书", "旅游"] };
async def main(args: Args) -> Output:
params = args.params
# 构建输出对象
ret: Output = {
"key0": params['input'] + params['input'], # 拼接两次入参 input 的值
"key1": ["hello", "world"], # 输出一个数组
"key2": { # 输出一个Object
"key21": "hi"
},
}
return ret快速入手代码节点来编辑代码
(1)代码节点定义输入变量
async def main(args: Args) -> Output:
params = args.params对于我们在可视化节点输入的变量会自动出现在 params 字典中,我们只需要按名存取即可。
(2)在代码中取出输入
async def main(args: Args) -> Output:
params = args.params
# 按你定义的变量名直接取值
user_name = params.get('user_name', '匿名用户')
age = int(params['age']) # 数字需要类型转换
query_list = params['query_list'] # 列表/文本都按字符串传入在代码中直接使用变量来赋值就可以使用
在接受文本数据是可以使用.get()方法来防止代码没有抓取成功导致的报错
所有输入原始类型都是 str,如果需要数字、列表等,请手动转换。
(3)函数main内部编写代码逻辑
def reverse_and_count(s: str):
return s[::-1], len(s)
async def main(args: Args) -> Output:
params = args.params
text = params['input_text']
reversed_text, length = reverse_and_count(text)
# 准备输出
ret: Output = {
"reversed": reversed_text,
"length": length
}
return ret在main函数内部进行输入和输出,得到结果
(4) 返回输出字典
ret: Output = {
"result_string": "处理完成", # 字符串
"result_number": 42, # 数字
"result_list": ["A", "B", "C"], # 列表
"result_object": {"code": 200} # 嵌套对象
}
return retmain 函数 必须返回一个字典,字典的每个键就是一个输出变量名。下游节点可以直接用 {{代码节点名称.key}} 引用。
在 Coze(扣子)的工作流代码节点中,你在代码编辑器里 return 的数据结构,与你在节点配置面板中手动添加的“输出(Output)”参数,必须保持绝对一致(包括变量名和数据类型)。
因此,在写复杂代码前,先在面板上定义好输入(Input)和输出(Output)的变量名与类型,然后再进入代码编辑器,严格按照这个定义去编写 args 的读取和 return 的拼装。这样可以最大程度避免低级的变量名拼写错误。
科技资讯标题格式化联系(字符串处理与 .get() 防崩溃)
场景描述: 假设你的工作流需要抓取一些科技文档或资讯,然后推送到某个平台上。这个节点的作用是给抓取到的文章标题加上统一的标签,并统计字符长度。如果上游节点漏传了数据,代码需要能自动使用默认值。
1. 面板配置(UI 界面)
输入 (Input):
title(String) - 文章原始标题tag(String) - 资讯标签
输出 (Output):
final_title(String) - 加上标签后的最终标题char_count(Integer) - 标题总长度
2. 代码实现
Python
async def main(args: Args) -> Output:
params = args.params
# 使用 .get() 获取输入,并设置默认值以防上游漏传参数
raw_title = params.get('title', '未命名科技资讯')
news_tag = params.get('tag', '技术动态')
# 核心逻辑:拼接字符串并计算长度
formatted_title = f"【{news_tag}】{raw_title}"
length = len(formatted_title)
# 构建并返回输出对象,这里的 key 必须与输出面板完全一致
ret: Output = {
"final_title": formatted_title,
"char_count": length
}
return ret言归正传,对于这个数据类型转换代码
输入
Excel 提取出来的内容
列名
id
输出
信息列表,分类好的 id 和信息 对
完整代码如下:
# 在这里,您可以通过 'args' 获取节点中的输入变量,并通过 'ret' 输出结果
# 'args' 已经被正确地注入到环境中
# 下面是一个示例,首先获取节点的全部输入参数params,其次获取其中参数名为'input'的值:
# params = args.params;
# input = params['input'];
# 下面是一个示例,输出一个包含多种数据类型的 'ret' 对象:
# ret: Output = { "name": '小明', "hobbies": ["看书", "旅游"] };
import json
def extract_column(data_str: str, column: str) -> list:
"""
从 data["output"] 字段解析 JSON 列表,并提取指定列值列表
:param data: 原始输入(dict)
:param column: 要提取的列名(String)
:return: 包含所有列值的 list
"""
# 1) 去掉转义
data_str = data_str.replace('\\\"', '"')
rows = json.loads(data_str)
# 提取列
result = [row.get(column) for row in rows]
return result
async def main(args: Args) -> Output:
params = args.params
input = params["input"]
msg_column_name = params["msg_column_name"]
msg_id_name = params["msg_id_name"]
msg_list = extract_column(input, msg_column_name)
msg_id_list = extract_column(input, msg_id_name)
msg_list = [{"id": msg_id_list[i], "msg": msg} for i, msg in enumerate(msg_list)]
# 构建输出对象
ret: Output = {
"msg_list": msg_list
}
return ret第二条工作流集成了第一条工作流,具体如下
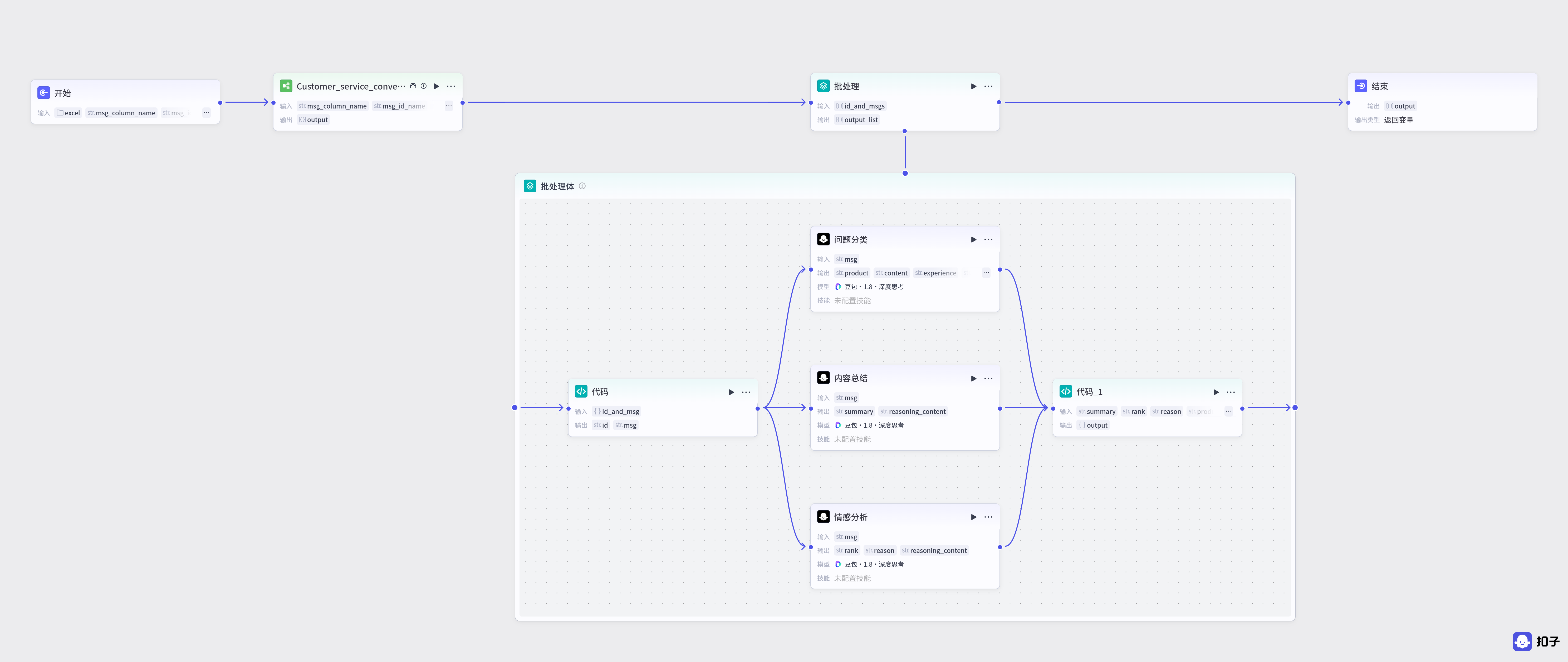
将第一条工作流处理好的id 和 信息集成好的数据放进批处理节点中进行处理,批处理中,第一个代码的作用是将id 和信息分离出来,具体代码如下:
输入是 id 和信息的集成形式
输出是 id 和信息两条分开的数据
import json # 如果不再需要可删除
async def main(args: Args) -> Output:
params = args.params
data = params["id_and_msg"]
# 判断数据类型:如果是字符串,则处理;如果是字典,直接使用
if isinstance(data, str):
data = data.replace('\\"', '"')
data = json.loads(data)
ret: Output = {
"id": data["id"],
"msg": data["msg"]
}
return ret其次,对于客服问题进行 问题分类,内容总结,情感分析,将得到的结果全部输出,代码节点用来提取数据
# 在这里,您可以通过 'args' 获取节点中的输入变量,并通过 'ret' 输出结果
# 'args' 已经被正确地注入到环境中
# 下面是一个示例,首先获取节点的全部输入参数params,其次获取其中参数名为'input'的值:
# params = args.params;
# input = params['input'];
# 下面是一个示例,输出一个包含多种数据类型的 'ret' 对象:
# ret: Output = { "name": '小明', "hobbies": ["看书", "旅游"] };
async def main(args: Args) -> Output:
params = args.params
# 构建输出对象
ret: Output = {
"output":{
"summary": params['summary'],
"product": params['product'],
"content": params['content'],
"experience": params['experience'],
"rank": params['rank'],
"reason": params["reason"],
"msg_id": params['msg_id'],
"msg": params['msg']
}
}
return ret对于整个文件批处理后结束。